
Cet article est le troisième et dernier article d’une série consacrée au développement. Ainsi, si vous ne l’avez pas déjà fait, nous vous conseillons vivement de lire attentivement les précédents articles. Le premier puis le deuxième, sans quoi vous risqueriez d’avoir du mal à suivre celui-ci.
Nous allons commencer par vous donner la solution commentée de l’exercice proposé à la fin de l’article précédent.
Nous aborderons ensuite la thématique de la gestion de projet de manière plus approfondie. Ainsi, même si vous n’êtes pas un développeur débutant ou confirmé, vous trouverez au sein de ce chapitre des conseils pour collaborer dans les meilleures conditions avec les développeurs de votre projet.
Pour finir nous aborderons rapidement des sujets plus complexes, qui pourraient cette fois être utiles même à des développeurs confirmés.
Solution de l’exercice
Pour rappel, voici l’énoncé de l’exercice que nous vous avions proposé :
- Lorsqu’un administrateur inscrit la commande “/firework NomDuJoueur” le joueur concerné est enregistré au sein d’une liste tandis que l’administrateur obtient un message de confirmation. Si l’administrateur réinscrit cette même commande, le joueur est supprimé de la liste. Là encore, un message de confirmation est envoyé à l’administrateur.
- Lorsqu’un joueur saute alors qu’il fait partie de cette liste, il s’envole dans les cieux, propulsé par des explosions sous ses pieds. Au cours de son ascension, une traînée de particules apparaît derrière lui. On entend également le bruit caractéristique d’une fusée d’artifice. Enfin, lorsqu’il atteint une certaine altitude, le joueur meurt et l’on peut voir une explosion de feux d’artifices (Whooo, une belle bleue !).
Et voici ce que ça donne en jeu (lorsque l’on réalise cette commande sur nous même) :
Chose promise chose dûe : voici la solution implémentée et commentée !
package fr.skytale.skytuto;
import org.bukkit.Bukkit;
import org.bukkit.plugin.java.JavaPlugin;
import java.util.HashSet;
import java.util.UUID;
/* Pour rappel ceci est la classe principale de notre plugin.
C'est celle dont la méthode onEnable sera appelée au lancement du serveur.
Elle possède une seule instance (cf tutoriels conception orientée objets de l'article précédent).
*/
public final class FireworkPlugin extends JavaPlugin {
// Nous créons une variable instance statique (cf design pattern singleton).
private static FireworkPlugin instance;
// Nous créons la liste qui contiendra les joueurs devant s'envoler lors d'un saut.
private HashSet<UUID> fireworkPlayers;
/* Nous créons une méthode static permettant d'accéder, depuis n'importe quelle classe / instance d'autres classes,
à l'instance principale de notre JavaPlugin.
*/
public static FireworkPlugin getInstance() {
return instance;
}
/*
La méthode onEnable est appelée au démarrage du serveur.
Pour faire cela, Bukkit/Spigot va créer une nouvelle instance de notre JavaPlugin :
JavaPlugin plugin = new FireworkPlugin()
Puis appeler cette méthode :
plugin.onEnable()
Bien sûr c'est une simplification faite pour vous donner une idée de ce que fait Spigot.
*/
@Override
public void onEnable() {
// Nous stockons l'instance de notre plugin dans l'attribut statique instance.
instance = this;
/* Nous initialisons notre Set des joueurs qui devront s'envoler lorsqu'ils sauteront.
C'est désormais une collection vide que nous pourrons remplir selon les commandes envoyées par les
administrateurs.
*/
fireworkPlayers = new HashSet<>();
/* Nous initialisons et nous inscrivons notre MoveListener pour qu'il puisse écouter les événements de
déplacement des joueurs.
*/
Bukkit.getPluginManager().registerEvents(new MoveListener(), this);
/* Nous initialisons et nous inscrivons notre FireworkCommand pour qu'il puisse réagir aux commandes
envoyées par les joueurs.
*/
Bukkit.getPluginCommand("firework").setExecutor(new FireworkCommand());
}
// Cette méthode, inutilisée pour l'instant, sera appelée à l'arrêt du plugin.
@Override
public void onDisable() { }
/* Grâce à cette méthode, nous pourrons récupérer les joueurs qui doivent s'envoler depuis d'autres classes de notre
plugin.
*/
public HashSet<UUID> getFireworkPlayers() {
return fireworkPlayers;
}
}package fr.skytale.skytuto;
import org.bukkit.Bukkit;
import org.bukkit.command.Command;
import org.bukkit.command.CommandExecutor;
import org.bukkit.command.CommandSender;
import org.bukkit.entity.Player;
import java.util.HashSet;
import java.util.UUID;
// C'est la classe qui recevra les commandes /firework (ou tout autre alias de cette commande).
public class FireworkCommand implements CommandExecutor {
/* Nous créons quelques constantes qui serviront à envoyer des messages aux joueurs.
Les "%s" sont des espaces où nous allons injecter du texte, ici l'alias utilisé pour appeler la commande ou le
nom du joueur.
*/
public static final String USAGE_PLAYER = "Usage : /%s <player>";
public static final String NO_PLAYER = "The player %s does not exist.";
public static final String ROCKET_ON = "Kisses %s, have a good trip to Mars ! ;)";
public static final String ROCKET_OFF = "It is nice to feel the ground beneath your feet, isn't it %s ?";
// Voici la méthode qui recevra les commandes envoyées par les joueurs ou par la console ou par un bloc de commande.
@Override
public boolean onCommand(CommandSender sender, Command command, String label, String[] args) {
/* Nous vérifions :
Est-ce que l'émetteur de la commande est administrateur ? Ce sera le cas si le joueur est administrateur ou
si la commande est envoyée depuis la console ou depuis un bloc de commande.
Est-ce que la commande envoyée est bien firework ? Nous utilisons command.getName() pour cela car label peut
contenir un alias (par exemple "/fw").
Étant donné que nous n'avons inscrit ce CommandExecutor que pour la récépetion de la commande "firework",
dans notre méthode onEnable de Firework plugin, ce test est superflue.
*/
if (!sender.isOp() || !command.getName().equalsIgnoreCase("firework")) {
// Nous arrêtons l'exécution et renvoyons false pour signifier que la méthode n'a pas fonctionné.
return false;
}
// La méthode ne fonctionne que s'il y a 1 et 1 seul paramètre,c'est-à-dire le nom du joueur.
if (args.length != 1) {
// Nous envoyons alors un message pour informer l'utilisateur de la manière d'utiliser cette commande.
sender.sendMessage(String.format(USAGE_PLAYER, label));
//Nous arrêtons l'exécution mais la commande a fonctionné (donc nous renvoyons "true").
return true;
}
// Nous cherchons et stockons un joueur connecté qui posséderait ce nom.
Player player = Bukkit.getServer().getPlayer(args[0]);
// S'il n'existe pas de joueur connecté portant ce nom.
if (player == null) {
/* Nous envoyons alors un message pour informer l'utilisateur du fait qu'aucun joueur portant ce nom n'a été
trouvé.
*/
sender.sendMessage(String.format(NO_PLAYER, args[0]));
//Nous arrêtons l'exécution mais la commande a fonctionné (donc nous renvoyons "true").
return true;
}
/* Nous récupérons, grâce à la méthode statique getInstance créée dans FireworkPlugin, une instance de notre
plugin.
Depuis cette instance, nous récupérons la collection des joueurs devant s'envoler au moindre saut.
A ce stade, il s'agit de comprendre que cette collection n'est pas une copie mais bien un pointeur vers la
collection présente dans FireworkPlayers. Autrement dit, si nous ajoutons ou supprimons un joueur de cette
collection ici, il sera aussi ajouté ou supprimé dans la collection présente dans FireworkPlugin.
*/
HashSet<UUID> fireworkPlayers = FireworkPlugin.getInstance().getFireworkPlayers();
// Nous créons une variable qui contiendra un message à envoyer à l'émetteur de la commande et au joueur concerné.
String message;
// Si le joueur fait déjà partie de la liste.
if (fireworkPlayers.contains(player.getUniqueId())) {
// Nous le supprimons de la collection.
fireworkPlayers.remove(player.getUniqueId());
// Nous remplissons le message à envoyer.
message = String.format(ROCKET_OFF, player.getName());
} else { // Si, au contraire, le joueur ne fait pas déjà partie de la liste.
// Nous l'ajoutons dans la collection.
fireworkPlayers.add(player.getUniqueId());
// Nous remplissons le message à envoyer.
message = String.format(ROCKET_ON, player.getName());
}
//Nous envoyons un message à l'émetteur de la commande (si ce n'est pas la même personne que le joueur ciblé).
if (sender != player) {
sender.sendMessage(message);
}
//Nous envoyons le message au joueur concerné.
player.sendMessage(message);
//Nous terminons l'exécution en précisant que la commande a fonctionné.
return true;
}
}package fr.skytale.skytuto;
import org.bukkit.*;
import org.bukkit.entity.Firework;
import org.bukkit.entity.Player;
import org.bukkit.event.EventHandler;
import org.bukkit.event.Listener;
import org.bukkit.event.player.PlayerMoveEvent;
import org.bukkit.inventory.meta.FireworkMeta;
import org.bukkit.util.Vector;
import java.util.HashMap;
import java.util.HashSet;
import java.util.UUID;
// C'est la classe qui sera chargée de réagir aux déplacement des joueurs.
public class MoveListener implements Listener {
/* Nous avons légèrement dépassé l'énoncé de l'exercice que nous vous avons transmis à la fin de l'article
précédent. Nous avons eu envie de créer une petite animation de particules.
Ainsi, nous définissons ici quelques constantes qui servent de paramètres à l'animation de particule, vous pouvez
les modifier pour voir comment elles impactent l'animation.
*/
// La taille du cercle de particules qui apparaît derrière le joueur.
public static final double RADIUS = 2.0;
// Le nombre de points qui constitue le cercle de particules.
public static final int NB_POINTS = 20;
// L'angle entre deux points en radian.
public static final double STEP_ANGLE = 2 * Math.PI / NB_POINTS;
// La hauteur où le joueur sera brutalement assassiné.
public static final double DEATH_HEIGHT = 500.0;
public static final String BYE_EARTH = "Bisous, je m'envole !";
// Pour chaque joueur, nous stockons la hauteur de son ascension vers les cieux au fur et à mesure de son vol.
private HashMap<UUID, Double> playersFlyHeight;
/* Lors de notre animation de particules, nous avons eu envie de faire comme si le joueur avait deux réacteurs :
Un à gauche et l'autre à droite. Ainsi, il faut qu'à chaque déplacement, nous affichions les particules soit à
droite, soit à gauche, par alternance.
Ainsi pour cette alternance, nous avons besoin de savoir quel côté sera affiché lors du prochain déplacement.
C'est pour cela que nous stockons, pour chaque joueur, ce côté de la propulsion sous la forme d'un boolean,
c'est-à-dire d'une variable qui peut être soit vraie, soit fausse.
*/
private HashMap<UUID, Boolean> playersPropulsionSideSwitch;
// C'est la liste des joueurs qui devront s'envoler.
private HashSet<UUID> fireworkPlayers;
/* C'est le constructeur de cette classe, il est appelé à chaque fois que l'on crée une nouvelle instance sans
préciser de paramètre : new MoveListener().
*/
public MoveListener() {
// Nous initialisons la map de hauteur de vol par joueur.
playersFlyHeight = new HashMap<>();
// Nous initialisons la map de côté de propulsion par joueur.
playersPropulsionSideSwitch = new HashMap<>();
// Nous récupérons un pointeur vers la collection des joueurs qui devront s'envoler.
fireworkPlayers = FireworkPlugin.getInstance().getFireworkPlayers();
}
/* C'est la méthode appelée à chaque déplacement d'un joueur.
Elle ne fonctionne que parce que l'on a ajouté l'annotation @EventHandler et parce que l'on a inscrit cette
instance comme étant à l'écoute d'événements au sein de la méthode onEnable de notre plugin FireworkPlugin.
*/
@EventHandler
public void onMove(PlayerMoveEvent event) {
// Nous récupérons le joueur qui s'est déplacé.
Player player = event.getPlayer();
/* Nous récupérons l'UUID du joueur concerné car nous allons l'utiliser de nombreuses fois dans la suite de
cette méthode.
*/
UUID playerUUID = player.getUniqueId();
/* Nous vérifions que:
- Le joueur fait partie de la liste des joueurs qui doivent s'envoler ;
- Nous vérifions que le joueur a une vitesse (= vélocité) verticale positive.
- Nous vérifions que le joueur n'est pas en train de nager ou de sortir de l'eau.
- Nous vérifions que le joueur n'est pas en train de voler (en créatif).
- Nous vérifions que le joueur est monté lors de ce déplacement.
En somme, ces conditions sont vérifiées lorsque notre joueur saute ou lorsqu'il est en train d'être propulsé
vers le haut par des explosions, comme ce sera le cas au cours de son ascension.
Pour plus d'informations sur ces conditions, n'hésitez pas à vous reporter à l'article précédent.
*/
if (fireworkPlayers.contains(playerUUID) &&
player.getVelocity().getY() > 0 &&
!event.getFrom().getBlock().isLiquid() &&
!player.isFlying() &&
event.getFrom().getBlockY() < event.getTo().getBlockY()
) {
// Nous récupérons l'emplacement actuel du joueur.
Location playerLocation = player.getLocation();
/* Nous récupérons l'altitude actuelle du vol du joueur.
Cette valeur n'est pas l'altitude en général. C'est l'altitude du vol. Donc la différence avec le sol.
Autrement dit, si un joueur est déjà à un emplacement situé à 200 blocs de haut au sein de notre monde
avant qu'il ne saute, puis qu'il vole sur 50 blocs de hauts, la valeur de flyHeight sera 50 et non pas 250.
Attention, nous avons récupéré la valeur dans playersFlyHeight mais c'est une copie. Ainsi il faudra penser
à la remettre à jour dans playersFlyHeight plus tard, lorsque nous l'aurons faite évoluer.
*/
Double flyHeight = playersFlyHeight.get(playerUUID);
/* Si le joueur n'a pas encore commencé à voler.
Autrement dit s'il n'est pas présent dans la map playersFlyHeight.
*/
if (flyHeight == null) {
// Nous initialisons la hauteur du vol à 0 (le "d" provient du fait que flyHeight est un Double).
flyHeight = 0d;
// Nous lançons le son (qui ne sera donc joué qu'une seule fois : au moment du saut).
player.playSound(playerLocation, Sound.ENTITY_FIREWORK_ROCKET_LAUNCH, 300f, 0.5f);
/* Nous envoyons un message en se mettant à la place du joueur qui s'envole. Autrement dit, c'est le
joueur qui s'envole qui informe les autres joueurs du serveur de son décollage.
*/
player.chat(BYE_EARTH);
}
/* Nous augmentons la hauteur du vol en fonction du déplacement qui est effectué.
C'est-à-dire en fonction de la différence entre le point de départ et le point d'arrivé sur l'axe Y.
*/
flyHeight += event.getTo().getBlockY() - event.getFrom().getBlockY();
player.setNoDamageTicks(1);
/* Nous créons l'explosion sous les pieds du joueur avec une puissance de 15 (le "f" provient du fait que
flyHeight est un float).
*/
player.getWorld().createExplosion(playerLocation, 5f);
player.setVelocity(new Vector(0,5,0));
/* A partir de là nous allons créer la traînée de particules.
Nous aurions pu, en suivant l'énoncé, nous contenter de créer une particule sous les pieds du joueur
grâce à l'instruction ci-après.
- Nous aurions choisi arbitrairement la particule Particle.CAMPFIRE_COSY_SMOKE.
- Nous aurions affiché la particule aux pieds du joueur player.getLocation().
- Nous aurions affiché 1 particule.
- Nous l'aurions affiché à cet emplacement précis (et non pas dans une zone). Donc nous aurions défini
0, 0, 0 pour la taille du cuboid d'affichage. C'est-à-dire que la particule serait apparue directement
aux pieds du joueur et non pas dans un pavé situé entre les pieds du joueur et un autre emplacement.
- Et enfin nous aurions donné à la particule une vitesse de 1.
Cela aurait donc donné l'instruction suivante :
*/
// player.getWorld().spawnParticle(Particle.CAMPFIRE_COSY_SMOKE, player.getLocation(), 1, 0, 0, 0, 0);
/* Mais nous avons eu envie d'aller un peu plus loin :
- D'abord nous avons souhaité créer un cercle de particules.
- Ensuite nous avons souhaité aller encore plus loin en alternant deux demi-cercles tour à tour, un peu
comme si le joueur avait deux réacteurs qui s'activaient en alternance.
Ainsi tout le code ci-après peut être commenté et remplacé par l'instruction ci-dessus.
*/
// ------- DÉBUT DE LA PARTIE OPTIONNELLE POUR L'ANIMATION DE PARTICULES -------//
// Pour savoir quel réacteur activer, nous récupérons l'information depuis la map correspondante.
Boolean propulsionSideSwitch = playersPropulsionSideSwitch.get(playerUUID);
/* On initialise arbitrairement la valeur à true si jamais le vol vient de débuter et que l'on ne sait quel
"réacteur doit être activé".
*/
if (propulsionSideSwitch == null) {
propulsionSideSwitch = true;
}
// Pour chaque point du cercle de particules à afficher :
for (int p = 0; p < NB_POINTS; p++) {
/* Nous trouvons l'angle du Nième point à afficher en radian.
Pour cela nous nous basons sur la différence d'angle entre deux points.
*/
double theta = p * STEP_ANGLE;
/* Nous allons déterminer si l'on doit afficher la particule du cercle en fonction de deux
informations :
- propulsionSideSwitch : Est-ce que c'est le réacteur droit ou gauche qui doit être allumé lors
de ce déplacement ?
- theta : Est-ce que la valeur de theta indique que nous sommes en train de dessiner la partie droite
ou la partie gauche du cercle de particule ?
On affiche une particule SI, au choix :
- Le réacteur droit est allumé ET on est en train de travailler sur un point de la première moitiée
du cercle de particules.
- Le réacteur gauche est allumé ET on est en train de travailler sur un point de la seconde moitiée
du cercle de particules.
Pour plus d'informations sur theta et ses valeurs vous pouvez consulter cette page :
https://www.geogebra.org/m/ayafxCkR
*/
boolean showParticle = (propulsionSideSwitch && theta >= Math.PI) || (!propulsionSideSwitch && theta < Math.PI);
// Si cette particule ne doit pas être affichée :
if (!showParticle) {
/* Alors ce point (cette particule) ne nous intéresse pas, passons au suivant. C'est à dire à l'étape suivante de
notre boucle for.
*/
continue;
}
/* A partir de cet angle theta en radian nous calculons l'emplacement de la particule à afficher.
L'altitude (la position du joueur sur l'axe Y).
Les positions sur les axes X et Z sont déterminées à partir de la position des pieds du joueur.
Mais on modifie leur valeur en utilisant un peu de trigonométrie.
Cela fait référence à des connaissances que vous avez sûrement appris en cours mais, pour plus
d'informations vous pouvez consulter cette page : https://www.geogebra.org/m/ayafxCkR
*/
double x = playerLocation.getX() + (RADIUS * Math.cos(theta));
double y = playerLocation.getY();
double z = playerLocation.getZ() + (RADIUS * Math.sin(theta));
// A partir de ces valeurs calculés, nous définissons la nouvelle localisation de la particule.
Location particleLocation = new Location(player.getWorld(), x, y, z);
// Nous affichons la particule à la position calculée.
player.getWorld().spawnParticle(Particle.CAMPFIRE_COSY_SMOKE, particleLocation, 1, 0, 0, 0, 0);
}
/* Nous allons inverser la valeur de propulsionSideSwitch pour que le prochain réacteur à s'allumer soit de
l'autre côté. Puis nous sauvegardons cette valeur dans la map playersPropulsionSideSwitch.
*/
playersPropulsionSideSwitch.put(playerUUID, !propulsionSideSwitch);
// ------- FIN DE LA PARTIE OPTIONNELLE POUR L'ANIMATION DE PARTICULES -------//
// Si le joueur dépasse la hauteur limite :
if (flyHeight > DEATH_HEIGHT) {
// On tue le joueur.
player.setHealth(0);
flyHeight = null;
// Création du feu d'artifice à la position du joueur.
Firework firework = player.getWorld().spawn(playerLocation, Firework.class);
//Ajout d'effets sur ce feu d'artifice.
FireworkMeta fm = firework.getFireworkMeta();
fm.addEffect(FireworkEffect.builder()
.flicker(true) //Clignotement.
.trail(true) //Traînée.
.with(FireworkEffect.Type.BALL_LARGE) //Forme.
.withColor(Color.YELLOW) //Couleur principale.
.build());
fm.setPower(1);
firework.setFireworkMeta(fm);
//Son de l'explosion du feu d'artifice.
player.playSound(playerLocation, Sound.ENTITY_FIREWORK_ROCKET_TWINKLE, 300f, 0.5f);
}
// Nous mettons à jour, dans la map, la nouvelle valeur de hauteur du vol pour ce joueur.
playersFlyHeight.put(playerUUID, flyHeight);
}
}Le code est disponible dans son intégralité sur ce dépôt (dans la branche “correctionFusee”).
Comme précisé dans l’article précédent, nous vous conseillons vivement de créer un nouveau monde de manière à éviter de détruire vos constructions lorsque vous testerez cette fonctionnalité. Si vous avez envie de vous amuser avec, sachez que le désert est un biome adapté pour essayer cela. Et voici une seed adaptée pour que vous puissiez apparaître en plein désert : “-4099434556615951558”).

Gestion de projet
Le développement est un travail long et complexe et, surtout dans le cadre de projets de grande envergure impliquant plusieurs développeurs. Il est absolument nécessaire d’organiser le travail à réaliser.
La gestion de projet peut être réalisé de bien des manières. Néanmoins, on y trouvera toujours des réponses méthodologiques à des problématiques courantes :
- Savoir ce qu’il faut faire.
- Comprendre comment le faire.
- Savoir dans quel ordre faire les choses.
- Pour éviter de bloquer d’autres membres du projet.
- Pour parer à la démotivation et les difficultés qui résultent d’une vision floue d’une gigantesque montagne de travail.
- Ou encore pour avoir rapidement une première version fonctionnelle, que l’on peut présenter lors d’une démonstration.
- Détecter les problèmes (bugs ou écarts par rapport au besoin) et les solutionner.
- S’assurer que chacun est à la place qui lui convient.
- Un développeur débutant, non accompagné, travaillant sur le cœur d’un système complexe, c’est extrêmement risqué.
- Un développeur expérimenté travaillant sur une tâche simple, répétitive et rébarbative risquerait de vite se démotiver et d’être donc moins efficace.
Une bonne méthodologie de projet permettra toujours, au minimum, de répondre à ces cinq besoins.
Différentes méthodes projet
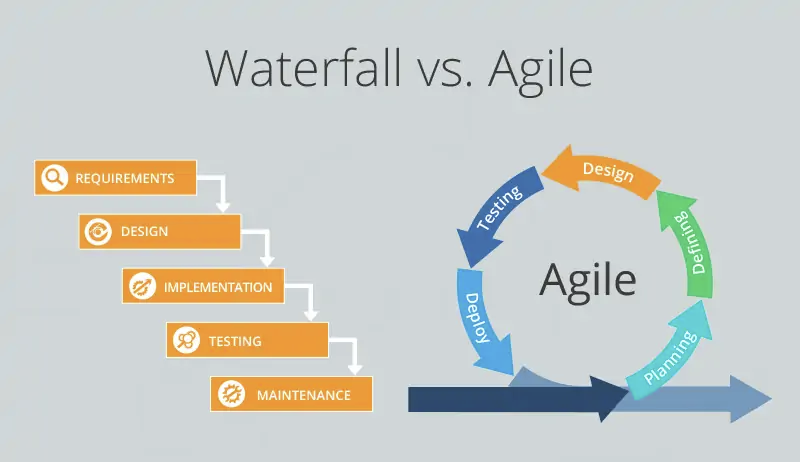
Aujourd’hui on trouve 2 visions différentes relativement opposées que l’on peut choisir d’utiliser pour mener un projet.
Les méthodes Waterfall d’un côté et les méthodes agiles de l’autre.

Les méthodes Waterfall sont plus anciennes mais largement éprouvées. Au contraire, les méthodes agiles sont plus récentes mais ont également fait leurs preuves.
Les méthodes Waterfall sont plus statiques et demanderont de réfléchir à chaque besoin avant de commencer. Il s’agit de faire les choses par étape, consciencieusement, puis d’éviter à tout prix de revenir sur ce qui a déjà été fait, décidé ou validé auparavant.
Les méthodes agiles permettent d’avancer partie par partie et de réorienter le besoin au fur et à mesure. Par contre elles nécessitent, entre autre-chose, la présence d’un lead développeur compétent et capable d’avoir une vision globale pour orienter les décisions à chaque étape.
En réalité, ces deux méthodes s’adaptent à des situations différentes et ont chacune leurs avantages et leurs inconvénients.
Pour en savoir plus sur ces méthodes, leurs avantages, leurs inconvénients et les contextes dans lesquels il est pertinent de choisir d’utiliser les unes ou les autres, nous vous conseillons de consulter cet article en français ou celui-ci en anglais.
Mais, pour simplifier, nous vous conseillons d’utiliser les méthodes Waterfall si vous êtes sur un petit projet. C’est souvent le cas lorsque l’on débute en développement Minecraft. Par contre, si votre projet est gigantesque et s’inscrit dans la durée, les méthodes agiles peuvent mieux vous convenir.
Étant donné qu’il est assez classique, aujourd’hui, sur Minecraft, de voir des projets faire appel à des externes pour réaliser leurs développements. C’est-à-dire payer un ou plusieurs développeurs, qui ne font pas partie du projet, pour réaliser leur plugin/mod/launcher/… Nous nous devons de préciser que, dans ce genre de cas, il est plus pertinent d’utiliser le modèle Waterfall.
Le suivi permanent des coûts, qui évoluent au fur et à mesure que le besoin est défini et réorienté, est quelque chose de laborieux qui nécessite une très bonne gestion de projet. Ce n’est donc pas quelque chose de facile à mettre en place et c’est pour cette raison que nous déconseillons les méthodes agiles dans des contextes de commandes de plugins, de mods ou de launchers. En effet, même dans des entreprises de développement informatique, la réévaluation permanente des coûts amène à voir des conflits prendre des proportions démesurées. Dans le contexte de plugins Minecraft, cela ne va généralement pas jusqu’au juridique mais se termine plutôt par l’abandon d’un projet, un non-paiement, ou encore bien d’autres conflits désagréables.
Dans tous les cas, nous n’insisterons jamais assez sur l’importance de définir et de communiquer ce que l’on souhaite obtenir.

Des logiciels efficaces
Bon, très bien, mais maintenant comment on s’y prend ?
Il existe tout un tas de logiciels facilitant la gestion de projet. Côté développement, nous conseillons d’utiliser un logiciel capable de s’interfacer avec GIT (voir l’article précédent). Une partie de ces logiciels sont payants et/ou très complexes à prendre en main. Ainsi nous n’avons listé ici que des logiciels relativement simples et gratuits :
- GitLab contient des fonctionnalités de gestion de projet. Vous pouvez lire cet article pour découvrir comment vous y prendre.
- Github contient lui aussi ce type de fonctionnalités.
- Open-Project est un logiciel open source. Il contient de nombreuses fonctionnalités même avec la version gratuite. Il peut lui aussi être lié à un dépôt GIT. Par contre, il est bien plus compliqué à utiliser. Qui plus est, il sera nécessaire de le déployer sur un serveur web pour profiter de la version gratuite. Ainsi, il n’est pertinent de l’utiliser que sur des projets de grande envergure.
- Taiga est un autre logiciel open source qui possède plus ou moins les mêmes avantages et inconvénients qu’Open-Project.
Cette liste n’a pas vocation à être exhaustive. Et vous pourrez probablement trouver bien d’autres logiciels, gratuits ou payants, répondant à vos besoins. N’hésitez donc pas à tester des logiciels ou à consulter des comparatifs.
Saisir les tâches et leurs interdépendances
Très bien, mais quelles sont ces “tâches” que l’on doit inscrire dans ce logiciel ?
On commence donc par créer des tâches qui correspondront à l’une ou l’autre des grandes étapes du développement. On peut choisir de détailler plus ou moins suivant le degré de précision que l’on souhaite obtenir dans notre suivi du projet. Voici une vision résumée (et non exhaustive) :
- La définition de ce qu’il faut réaliser.
- D’abord point de vue fonctionnel :
- La réalisation d’un cahier des charges.
- La réalisation de spécifications fonctionnelles détaillées.
- Ensuite, d’un point de vue technique :
- La réalisation de schémas d’architecture :
- Architecture logicielle (diagramme de classes/objets en UML).
- Structuration de la base de données (diagramme de classes/objets en UML ou MCD en Merise).
- Infrastructure technique (quels serveurs, quels logiciels interfacés avec quels autres logiciels).
- La réalisation de schémas d’architecture :
- D’abord point de vue fonctionnel :
- L’implémentation (ce que l’on va programmer).
- On divise en grandes parties. Puis en petites tâches compréhensibles et faisables en peu de temps (une tâche contient généralement ses propres tests unitaires).
- Les tests globaux.
- Tests d’intégration (maintenant que l’on a rassemblé tout le code, est-ce que tout ce qui marchait séparément fonctionne encore ?).
- Tests de non régression (depuis que l’on a rajouté de nouvelles fonctionnalités, est-ce que tout ce qui marchait précédemment fonctionne encore ?).
Ensuite, on inscrit leurs interdépendances (“Est-ce qu’il faut avoir fait ceci avant d’attaquer cela ?”) et leur durée (“Combien de temps cela va-t-il prendre ?”).
À partir de là on peut prioriser les tâches (“Qu’est-ce qui est le plus urgent ?”).
Puis on peut attribuer les tâches à telles ou telles personnes (“Ça je m’en occupe et toi tu pars là dessus ?”).
C’est très long et ça nécessite de cogiter sur pas mal de points. Mais, à partir du moment où l’on a réalisé tout ceci, on peut avoir une vision globale du projet et avancer tout en restant organisés et efficaces.
En effet, il suffira ensuite de mettre à jour le statut d’une tâche (“À faire” ⇒ “En cours” ⇒ “Terminé”) ainsi que son pourcentage d’avancement ou l’estimation du temps restant pour garder tout cela à jour.
Développement avancé – problématiques courantes
La grande majorité de nos articles était destinée à des développeurs débutants. À contrario, nous aborderons ici des problématiques bien plus techniques rencontrées par des développeurs expérimentés. Étant donné qu’entrer dans les détails de ces cas d’usage nécessiterait des pages et des pages d’explications, nous nous permettrons d’être plus concis mais vous trouverez toutes les informations dans les liens attenants. Voyez donc ce chapitre comme une bibliographie, une sorte d’annuaire.
Les patrons de conception (design pattern)
En développement, on retrouve régulièrement des problématiques similaires. Pour répondre à chacune de ces situations, il est pertinent d’utiliser un ou plusieurs modèles d’architecture logicielle. C’est ce que l’on nomme des patrons de conception ou design pattern en anglais.
Voici quelques liens que vous pouvez consulter si vous n’êtes pas déjà familier avec ces notions :
- En anglais, très clair et imagé.
- En français mais moins digeste [1] [2].
Interagir avec d’autres plugins (API/Events)
Lorsque l’on développe des mods sous Fabric ou des plugins sous Spigot/Paper, on peut être amené à interagir avec d’autres mods ou d’autres plugins.
Cela peut paraître complexe à première vue mais, en réalité, c’est plutôt simple. La seule complexité réside dans la compréhension et dans l’utilisation du code de l’autre développeur. La difficulté dépend donc largement de la complexité du plugin/mod avec lequel vous souhaitez interagir.
Prenons l’exemple de Spigot.
Il s’agira tout d’abord d’inclure le plugin/mods (ou l’API correspondante si le développeur a découpé son code ainsi) dans le fichier qui décrit votre build Maven/Gradle.
Dans un second temps, il vous sera nécessaire de modifier votre plugin.yml pour lui ajouter une dépendance (à travers “depend” ou “softdepend”).
A partir de là, il existe deux manières d’interagir : l’accès direct ou l’écoute d’événements.
Pour ce qui est de l’accès direct, le processus est assez simple : Il s’agit d’abord de récupérer la classe principale du plugin (et ainsi de vérifier que le serveur possède bien ce plugin dans son dossier “/plugins”).
PluginMainClass pluginName = (PluginMainClass)
getServer().getPluginManager().getPlugin("pluginName");A partir de là, on peut potentiellement accéder à tout le reste du plugin. Si ce n’est pas le cas, on peut toujours utiliser des moyens détournés (comme la réflexion que nous vous présenterons dans la suite de cet article).
La seconde technique, l’écoute d’événement, ne diffère pas de la manière classique de faire cela dans Spigot. La seule différence c’est qu’au lieu d’écouter un événement natif, envoyé par Spigot (comme le “PlayerMoveEvent”). On écoutera ici un événement créé et envoyé par le plugin avec lequel nous souhaitons interagir.
Gardez en tête que les développeurs de chaque plugin documentent comment faire tout cela. N’hésitez donc pas à vous reporter à leur documentation.
Automatisation et intégration continue
Qui dit développement dit construction, tests et déploiement. Et même si on a, lorsque l’on débute, l’habitude de faire tout cela à la main depuis son ordinateur, il est possible d’automatiser tout cela. Tout peut être fait automatiquement. Que ce soit la construction du projet (la compilation), le déclenchement des tests unitaires ou encore le déploiement du plugin sur un serveur Minecraft. Mais également le suivi du redémarrage du dit serveur.
Ainsi on peut potentiellement lancer la construction, test et déploiement dès lors qu’un développeur envoi son code sur un dépôt GIT ou encore lorsqu’il tag une version du projet. Les promoteurs et artisans de cette démarche se nomment des DevOps. Ils se caractérisent principalement par la promotion de l’automatisation et du suivi (monitoring) de toutes les étapes de la création d’un logiciel, depuis le développement jusqu’au déploiement, en passant par l’intégration, les tests et la livraison.
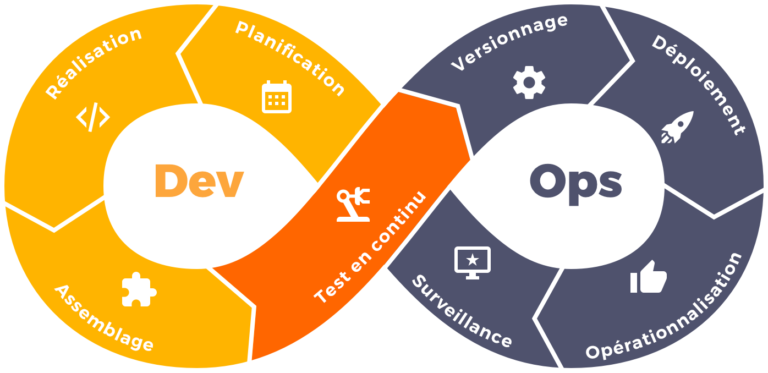
Il y aurait tant à dire… mais voici plutôt quelques liens qui pourront vous éclairer et vous guider dans cette démarche :
À ce sujet, nous exposions, dans l’article précédent, l’intérêt d’automatiser le déplacement du plugin généré lors du build vers le dossier plugin de notre serveur. Voici à nouveau les informations à ce sujet.
Stockage en JSON
Le yml, mis en avant par Spigot pour la gestion des fichiers de configuration de vos plugins, est assez pertinent dans bien des cas lorsqu’il s’agit de sauvegarder des données statiques simples.
region-restrictions: true
max-memory-percent: 95
enabled-components:
commands: true
plotsquared-hook: true
clipboard:
use-disk: true
compression-level: 1
delete-after-days: 1
name: plop
lighting:
delay-packet-sending: true
async: true
mode: 1
remove-first: true
do-heightmaps: truePar contre, il trouve vite ses limites et, dans de nombreuses situations, les développeurs préfèrent le format JSON. Voici un exemple pour les mêmes données :
{
"region-restrictions": true,
"max-memory-percent": 95,
"enabled-components": {
"commands": true,
"plotsquared-hook": true
},
"clipboard": {
"use-disk": true,
"compression-level": 1,
"delete-after-days": 1,
"name": "plop"
},
"lighting": {
"delay-packet-sending": true,
"async": true,
"mode": 1,
"remove-first": true,
"do-heightmaps": true
}
}Il est même possible d’aller très loin avec ce format. Par exemple en associant à une classe une logique permettant de sérialiser ou désérialiser ses instances. Voici quelques liens qui pourraient vous permettre de repenser la manière de stocker vos données configurables :
- Découvrir la sérialisation avec Gson (Le JSON de Google)
- Généraliser et avoir un système plus propre
La BDD (orm ? nosql/relationnel ?)
Tout projet avec des données variables se retrouve confronté à la problématique de leur stockage. Les bases de données sont là pour y répondre mais que choisir dans ce joyeux bor… cette large diversité ?

Allez-vous utiliser une BDD relationnelle ou NoSQL ? Voici quelques liens qui pourront vous aider à faire un choix en fonction des besoins de votre projet :
Et voici d’autres liens qui pourront vous présenter des manières pertinentes d’implémenter l’usage de ces BDD du côté de votre code Java. N’hésitez pas, avant de les consulter, à jeter un oeil à la notion d’ORM, un type d’outils qui pourrait simplifier vos développements :
- Implémentation BDD en Java
- Exemple d’ORM : Hibernate
Le synchrone/asynchrone ?
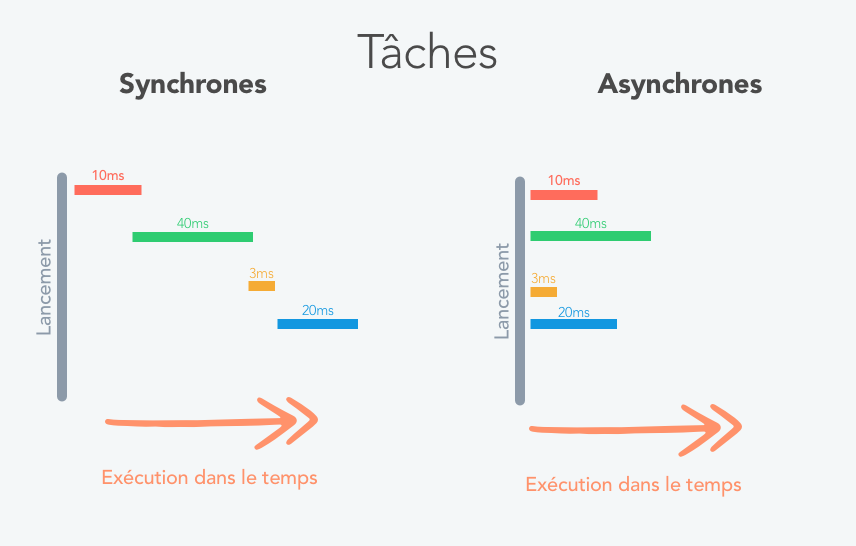
D’ordinaire et historiquement, dès lors que l’on envoie une requête, on attend la réponse avant de poursuivre l’exécution du code.
C’était par exemple le cas dans le vaste monde du développement web :
- Un navigateur (comme celui que vous utilisez actuellement pour voir cette page) demandait au serveur web d’afficher une page.
- Le code exécuté par le serveur web allait chercher une à une des informations en base de données. Par exemple la liste des commentaires et le contenu même de cet article.
- Puis, lorsqu’elles les avaient toutes récupérées, il assemblait toute la page pour ensuite la renvoyer au navigateur qui allait l’afficher sur l’écran.
Ainsi les données étaient demandées les unes après les autres. En reprenant notre exemple, cela amène à récupérer d’abord le contenu de l’article puis, la liste des commentaires avant de renvoyer l’ensemble dans une page web.
Envoyer et attendre une réponse avant de poursuivre l’exécution du code, c’est le principe d’une requête ou d’une fonction synchrone. Sauf qu’au risque de frôler le pléonasme, nous pourrions dire qu’attendre, c’est parfois assez long.

Pourquoi ne pas paralléliser ? Pourquoi ne pas envoyer les deux requêtes (contenu de l’article et liste des commentaires) en même temps à la base de données ? Puis, une fois les deux éléments récupérés, construire et retourner la page au navigateur de l’utilisateur ?
Ainsi, l’asynchrone devient progressivement la norme. Il s’agit d’envoyer une requête (ou d’appeler une fonction) et de ne traiter sa réponse que plus tard, lorsque cette dernière sera arrivée. L’intérêt de cette technique c’est qu’elle ne bloque pas la chaîne de traitement.
Dans le contexte de Minecraft cela se caractérise par exemple dans le traitement asynchrone de certaines des interactions avec la base de données. Cela permet de ne pas bloquer le serveur/processus pendant l’attente de la réponse.
Voici quelques sources qui devraient vous éclairer sur ce sujet complexe :
Le RayTracing et le calcul de collision
Vous avez peut-être entendu parlé du RayTracing avec les nouvelles technologies RTX qui sortent sur nos cartes graphiques et permettent un magnifique rendu de la lumière et des reflets avec un éclairage dynamique.
Mais outre son usage dans le cadre de la lumière, le RayTracing, c’est quelque chose d’omniprésent dans les jeux vidéo pour la gestion des projectiles qui se déplacent en ligne droite.
Réaliser du RayTracing et des calculs de collision devient vite indispensable pour concevoir certains types de gameplay. Que ce soit pour permettre aux joueurs de sortir leurs colts dans un saloon, les immerger dans une bataille spatiale à coups de blasters ou pour leur faire ressentir les frissons d’un duel de sorciers.
Le RayTracing, c’est, en somme, du calcul de trajectoire et d’intersection pour des lignes droites.
Ainsi, vous savez dès à présent que si vous souhaitez donner des trajectoires paraboliques à vos projectiles (comme pour une flèche) cette technique ne vous intéresse pas. Il faudra plutôt, dans ce cas, utiliser le système d’entité et de déplacement de Minecraft. Bien qu’il soit aussi possible de faire des calculs mathématiques complexes dans ce même cas.
Donc, si vous restez sur des lignes droites pour vos projectiles, il existe des outils, déjà programmés, qui permettent de simplifier un peu ces différentes situations dans Minecraft.

Pour ce qui est de Spigot, vous pouvez consulter la javadoc et chercher “RayTrace”. Vous tomberez sur de nombreuses méthodes permettant de faire cela à partir d’un monde, d’un bloc ou d’une entité vivante (joueur ou mob).
Par contre, si vous développez sur d’anciennes versions de Minecraft, ce lien devrait vous aider.
Si cela ne suffit pas à vos besoins, n’hésitez pas à faire des recherches sur internet. Par exemple “line plane intersection java”. En effet, nombreux sont les développeurs à avoir déjà rencontré et résolu les problèmes que vous rencontrez.
Enfin, si les méthodes plus mathématiques ne suffisent toujours pas à vos besoins, il vous est toujours possible de vérifier chaque étape du trajet de votre projectile (en divisant ce trajet en une multitude d’étapes). Cette dernière méthode peut d’ailleurs convenir aux trajectoires non linéaires.
Les animations de particules
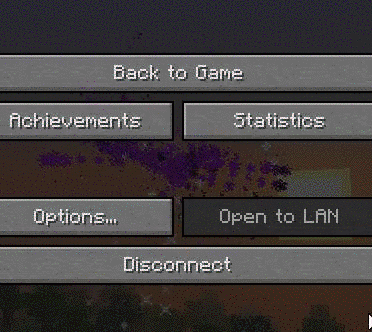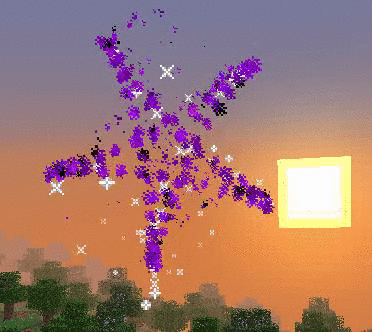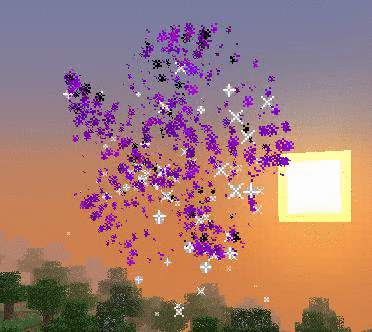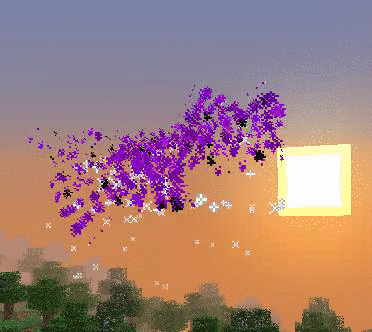
Les particules sont un magnifique moyen d’afficher des formes (animées ou non) dans l’espace.
Que ce soit pour créer un sort ou pour symboliser une explosion, elles amènent efficacement les joueurs à s’immerger dans les univers que l’on crée. Par contre, elles peuvent assez rapidement perturber l’expérience de jeu en provoquant des ralentissements. Il est donc important de les utiliser intelligemment et avec parcimonie.
Voici quelques liens qui vous guideront dans la conception d’animations de particules, des plus simples aux plus complexes :
Pour faire spawner vos particules ce tutoriel devrait pouvoir vous aider. Dans de nombreux cas, vous pouvez chercher sur internet un exemple de code commenté répondant à un usage précis. Vous pouvez taper par exemple, pour dessiner un cercle “spigot draw particle circle”). Cela pourrait vous amener, par exemple, sur ce tutoriel.
Mais nous vous conseillons plutôt de réviser les bases de la trigonométrie et de partir de là dans votre code. Ce n’est qu’ainsi que vous deviendrez autonome.
Ce lien vous permettra par exemple de comprendre l’équation paramétrique du cercle.
Si vous préférez le français, vous pouvez consulter ce lien. Cependant, il risque de vous rappeler vos cours de mathématiques de par sa forme).
Si vous vous accrochez, vous pourrez aller beaucoup plus loin et faire des choses incroyables. Vous pouvez vous baser par exemple sur ces liens :
Avec un peu d’entraînement et de la persévérance dans votre apprentissage de la trigonométrie, vous pourrez vite faire des choses étonnantes !
La réflexion ?
Java est un langage de programmation réflexif.
La première image permettant de comprendre le concept de réflexion, c’est le miroir : la réflexion en développement informatique c’est lorsque le code se regarde lui-même.
C’est-à-dire que la réflexion permet au développeur d’écrire, dans ses programmes, des instructions qui permettent d’examiner et de modifier les structures internes du programme en cours d’exécution.
Au demeurant, écrire dans votre programme ce type d’instructions tend à complexifier le code. Vous pouvez le voir dans cette introduction à la réflexion. Cela ne rendra donc pas votre code plus propre ou plus joli, bien au contraire.

Cependant, cela peut permettre de répondre à des besoins précis. Typiquement si vous voulez créer un gestionnaire d’extensions. C’est d’ailleurs ce qu’utilise le serveur Spigot pour charger les plugins alors qu’il ne sait pas, à l’avance, quels plugins sont présents dans le dossier /plugins/ du serveur.
Mais, outre ce besoin bien particulier, il y a d’autres contextes spécifiques à Minecraft, où la réflexion peut être utile : il s’agit de l’usage du NMS. Mais avant d’entrer dans les détails de cette pratique, nous vous invitons à consulter ces quelques liens :
Le NMS, réflexion ou inclusion ?
Le nom NMS provient de “net.minecraft.server” qui est le nom du package contenant le code du serveur officiel de Minecraft. Faire du NMS c’est interagir directement avec les classes et les méthodes du serveur Minecraft.
Comme expliqué dans le premier article, on évite en général de faire cela pour deux raisons principales : le code de Minecraft est difficilement lisible car offusqué. Qui plus est, les API (Bukkit, Spigot et Paper) servent d’intermédiaire et simplifient ces interactions.
Années après années, versions de Minecraft après versions de Minecraft, les développeurs de ces projets ont tellement amélioré et complété leur API que l’usage du NMS est devenu très rare.
À partir de Spigot/Paper pour Minecraft 1.16, dans la grande majorité des cas, les développeurs qui utilisent encore du NMS sont soit légèrement feignants et n’ont pas envie de modifier leur ancien code pour rechercher et utiliser les nouvelles techniques. Soit ils utilisent un système particulièrement étrange, ou soit ils cherchent à améliorer les performances en passant outre l’encapsulation faite par l’API.
Par contre, lorsque l’on développe pour des versions plus anciennes de Minecraft, l’usage du NMS devient souvent nécessaire. Que ce soit pour afficher un titre au milieu de l’écran ou pour programmer le comportement d’un monstre, il était souvent indispensable de l’utiliser car l’API ne contenait pas les méthodes nécessaires à ces cas d’usage.
Interagir avec le NMS est assez complexe mais, en somme, il existe deux méthodes :
- Utilisation du code natif de Minecraft (le NMS) lors de la compilation :
Si l’on utilise cette méthode il faut inclure des dépendances supplémentaires mais il sera ainsi possible d’accéder directement aux classes. Par contre votre code ne fonctionnera plus dès le moindre changement de version de Minecraft car les packages changent généralement d’une version à l’autre. À moins que vous ne fassiez différentes versions du code adaptées à chaque version, en appelant l’une ou l’autre suivant la version de Minecraft du serveur/client. - Utilisation de la réflexion :
Avec cette méthode, on peut accéder aux classes sans avoir à inclure de dépendance vers le code natif de Minecraft au sein de votre projet. Par contre cette méthode est plus coûteuse en ressources. C’est donc quelque chose qu’on préfère éviter d’utiliser dans certains cas, par exemple si l’on exécute cette partie du code très fréquemment.
Voici quelques liens qui expliquent l’usage du NMS par réflexion si jamais vous venez à en avoir besoin :
L’usage d’interfaces et de mock pour bosser en équipe
Mettons de côté le Java et Minecraft une seconde et prenons une situation fictive : vous souhaitez travailler avec d’autres personnes sur un projet informatique. Le projet est de grande envergure et il s’agit de diviser le travail. Il y a plusieurs grandes parties et chacun va travailler sur l’une d’entre elles. Qu’est-ce qui est nécessaire de mettre en place en premier pour permettre à chacun d’avancer sans bloquer les autres ?
Et bien tout simplement la manière dont ces grandes parties sont connectées, la manière dont elles communiquent entre elles, bref, leurs interfaces.
Revenons au Java et à une situation plus proche de notre sujet : la création d’un plugin ou d’un mod pour une map aventure. Dans ce cas là, si un développeur est, par exemple, en train de gérer la création d’un système de quêtes tandis qu’un autre avance sur la création d’une quête en particulier. Il faut donc commencer par créer l’interface qui va permettre à ces parties de communiquer.
En définissant et en créant cette interface chacun a les moyens d’avancer indépendamment. En effet, l’un des développeurs pourra utiliser cette interface tandis que l’autre pourra créer une classe qui implémente cette interface et réaliser son implémentation.
Une autre technique est de réaliser des mocks. Un mock est un bouchon. Il s’agit de renvoyer, par exemple lorsque l’on développe une API ou même une simple méthode, un code écrit en dur. Dans ce résultat, rien n’est variable. Le retour est donc un simple exemple de ce que pourrait renvoyer la méthode lorsqu’elle fonctionnera enfin.
Faire un mock c’est un bon moyen d’isoler et de tester une partie de votre code (grâce à Mockito). Mais, c’est également un bon moyen de bosser en équipe en permettant à un développeur de récupérer dès le début un résultat plausible lorsqu’il appelle votre code. De même, alors que vous n’avez pas terminé de développer votre partie du logiciel.
L’abstraction pour généraliser et aller plus loin
La majorité des développeurs ont tendance, du moins au début, à réaliser uniquement ce qui est nécessaire pour faire ce qui a été demandé et à ne pas aller plus loin, à ne pas abstraire. C’est normal mais cela peut nuire considérablement aux possibilités d’évolutions futures.
En effet, si l’on reprend l’exemple précédent, on peut imaginer plusieurs cas d’usage :
- Un plugin qui contient une quête jouable.
- Un plugin permettant aux développeurs de construire des quêtes et qui contient déjà une première quête jouable.
- Ou un plugin permettant aux développeurs et aux joueurs de construire des quêtes et qui contient déjà une première quête jouable.
- Ou encore un plugin capable de supporter des extensions ajoutant des quêtes qui permet aux développeurs et aux joueurs de construire des quêtes et qui contient déjà une première quête jouable. C’est-à-dire que d’autres plugins/mods/extensions/scripts/… pourront être chargés par ce plugin/mod et ils permettront l’ajout de quêtes.
Par contre, il ne faut pas confondre abstraction et complexité. Nous ne conseillons à personne de commencer par réaliser un gestionnaire d’extension. Par contre, programmer en mettant en place une architecture logicielle qui permettra plus tard de telles évolutions est extrêmement utile. En effet, si l’on ne prévoit pas, dès le début, une structure capable de supporter les potentielles évolutions futures, il est probable que l’on finisse par être bloqué à un moment. Il sera alors trop complexe et laborieux de tout restructurer (c’est-à-dire, selon le terme consacré en informatique, faire du refactoring).
L’abstraction est un concept très large et relativement complexe en informatique. Mais les points qui sont probablement les plus importants à retenir sont les suivants :
- Réfléchissez bien sur votre architecture orientée objet. Prenez le temps d’analyser avant de vous lancer dans le code. Visez la généralisation des problématiques. Maîtrisez bien la programmation orientée objet et créez des interfaces pour décrire les comportements communs ainsi que des classes abstraites pour généraliser les attributs et les comportements. Découpez les choses. Ne créez pas des classes à rallonge avec des milliers de lignes. Si une méthode est trop complexe, créez des sous méthodes. Et pour la santé mentale des personnes qui relieront votre code (vous y compris), choisissez des noms de méthodes, de paramètres, de classes et de variables clairs et représentatifs. Pour cela nous vous invitons à appliquer les principes SOLID.
- Prévoyez que tout puisse devenir configurable : ne rentrez JAMAIS une valeur en dur dans votre code et préférez l’usage de constantes (public static final). Ainsi, le jour où vous voudrez rendre cette variable configurable, cela sera facile d’aller remplir cette constante, devenue variable, depuis vos fichiers de configuration.
Même si ce chapitre était consacré à l’abstraction, voici quelques liens qui englobent cela et traitent, au final, de quelque chose de plus universel. C’est les bonnes pratiques de développement informatique.
Conclusion
Nous vous remercions d’avoir suivi nos articles sur le développement et espérons de tout cœur qu’ils vous auront été utiles !
Bien qu’il existe tout un tas d’espaces d’entraide, sachez que nous restons disposés à répondre à vos questions sur notre discord. Vous pouvez aussi jeter un œil au programme SkyAdvice sur notre site si vous souhaitez être accompagné sur l’ensemble de votre projet, développement compris.
À bientôt pour un autre Skytale Tuto qui traitera cette fois du voice acting !
Bonjour, merci de partager un si bon contenu avec nous. C’est vraiment un article instructif et étonnant, il m’aide aussi beaucoup.
Bonjour,
Déjà merci pour ton commentaire, au vu de sa taille on voit que tu t’investis et c’est toujours un plaisir de voir un tel intérêt surtout au vu de l’effort que cela a représenté pour nous.
Tu parles de quelques code smells. Nous sommes preneurs de tes suggestions d’amélioration si tu souhaites les détailler ici ou, plus simplement, en nous contactant sur discord. Si c’est pertinent nous n’hésiterons pas à faire des corrections/améliorations !
Pour le côté fourre-tout, nous entendons bien que ça peut être déroutant, mais c’est volontaire sur ce dernier article. Nous avons constaté que de nombreux développeurs ne pensaient pas à faire certaines choses, car ils n’avaient simplement pas connaissance de leur existence ou de leur utilité. Ainsi, sans pour autant avoir la prétention d’être exhaustifs, nous avons souhaité faire un petit tour d’horizons pour donner des pistes.
Concernant ta remarque sur l’opposition théorique entre l’idée de créer des maps aventures et le développement de plugin, nous avions répondu sur ce sujet à un commentaire dans le premier article. Vu que c’est le deuxième commentaire sur le sujet cela signifie que nous aurions dû expliquer pourquoi nous avons choisi de présenter tout cela plutôt que d’autres aspects.
Nous avons fait ce choix car développer des plugins est souvent un bon point de départ pour entrer dans le développement Minecraft. La majorité des développeurs commencent par là car ils cherchent à jouer en groupe. Une fois que l’on maîtrise le développement de plugins, il devient beaucoup plus facile de passer au développement de mods.
Qui plus est il est toujours possible, notamment quand on souhaite proposer des aventures multijoueurs, d’utiliser des plugins. On peut ainsi proposer au téléchargement un serveur préconfiguré et, à condition de faciliter son installation, cela peut permettre aux joueurs de jouer une aventure en groupe, avec leurs amis.
Par rapport à l’utilité de savoir faire du Java (et donc de dépasser le côté commandblock / datapack), il est clair que l’utilisation de ce langage de programmation permet d’aller plus loin : Un code objet bien structuré sera plus facile à faire évoluer qu’un datapack (au vu de ses limitations techniques). Cela permet donc d’aller plus loin dans la complexité. C’est vrai pour la création de modes comme de plugins.
Pour répondre à ta question sur la courbe de difficulté de ces tutoriels, nous tenons à dire que c’est très compliqué d’être à la fois exhaustif et didactique. Tout est donc affaire de compromis. Nous sommes d’accord avec toi sur l’idée qu’il vaut mieux apprendre le langage avant de commencer à développer sur Minecraft. En même temps, beaucoup de jeunes qui se sont mis au développement par Minecraft ont découvert les complexités de ce langage au fur et à mesure qu’ils mettaient en place des fonctionnalités au sein de leurs plugins/mods. Ils étaient enchantés de pouvoir constater directement en jeu les résultats de leurs expérimentations. C’est l’avantage de Minecraft.
La complexité de ce dernier article est excessive pour des débutants. Le souci, c’est que si l’on souhaite (et c’était notre vœu), fournir des informations permettant d’aller plus loin aux développeurs qui ont déjà un peu d’expérience, il est nécessaire de partir du principe que nos lecteurs ont suivi nos liens. C’est pourquoi nous avions insisté dès le début sur cette nécessité :
” Nous n’avons pas la prétention de pouvoir vous former, au sein de quelques articles, à des connaissances et des savoir-faire que les personnes acquièrent après quelques années d’expériences. Nous cherchons plutôt à vous donner une vision globale en vous apportant les informations nécessaires pour poursuivre votre formation en autonomie. C’est pour cette raison que nous avons agrémenté l’article de liens pour les plus curieux d’entre vous. ”
Et, au sein du deuxième article, après avoir accompagné nos lecteurs sur leurs premiers tâtonnements, nous leur avons transmis de nombreux tutoriels de qualité sur le Java et la POO.
“Voici quelques explications et tutoriels qui vous permettront d’aborder mieux le langage de programmation Java et la programmation orientée objet. Grâce à ces derniers, vous aurez enfin les moyens d’aller bien plus loin dans vos développements. Si vous souhaitez véritablement progresser, suivez les attentivement. N’hésitez pas à en voir plusieurs pour mieux retenir et compléter vos connaissances.
[…]”
Ainsi, comme tu l’as compris, dans ce dernier article, nous nous adressons aux développeurs ayant déjà un peu d’expérience ou aux personnes qui ont vraiment suivi le tutoriel en profondeur.
Tu parlais de la réflexion en Java, nous l’avons expliqué car, à nos yeux, c’est très utile pour comprendre ensuite la manière d’interagir avec le NMS. Beaucoup de personne souhaitant utiliser le NMS utilisent la réflexion sans la comprendre et ne sont donc pas autonomes.
Sur l’idée de recentrer l’explication sur le pourquoi, tu as raison, nous plaidons coupable. Comme de nombreuses personnes qui sont montées en compétence dans un domaine, nous oublions parfois de préciser les raisons d’être de telle ou telle chose, car elles nous paraissent déjà claires et évidentes.
Nous comprenons le risque que tu mets en évidence l’aspect contre-productif de toute cette complexité. Nous avons tenté de le prendre en compte en rassurant nos lecteurs de-ci de-là, mais c’est insuffisant. Il faudra donc revoir cela pour essayer d’insister un peu plus sur le fait qu’une application incomplète de ces méthodes n’empêche pas nécessairement d’avancer. Par contre, nous pensons que la vision globale qui découle de la découverte de tous ces aspects est pertinente pour que le lecteur pioche, ensuite, les éléments qui l’intéressent et qui conviennent à sa situation.
L’idée de diviser les articles aurait été pertinente, mais nous avions défini le nombre de 3 articles comme un maximum au sein de l’équipe.
Pour l’aspect RayCasting/RayTracing tu dois avoir raison, nous allons tenter de clarifier cela également.
Encore merci pour ton commentaire qui nous sera très utile lorsque nous auront le temps et l’énergie de reprendre ces articles en profondeur.
N’hésite pas à venir en parler avec nous sur notre discord. Si l’on arrive à construire ensemble un document pour lister toutes les améliorations à apporter, article par article, nous pourrons ensuite les appliquer pour le bien de nos lecteurs. Par contre, pour l’instant, l’équipe de développement se détourne un peu de la rédaction pour se recentrer sur ses activités habituelles (il faut savoir souffler un peu …) donc une telle refonte ne sera pas faite demain :D.
Nous te remercions pour ton retour ! Nous sommes ravis de t’apporter nos conseils, n’hésite pas à consulter l’ensemble des articles pour plus d’informations :)
Hey !
Bon tout d’abord, le contenu de l’article est assez intéressant et bien écrit, on voit que la personne qui l’a fait a de bonnes connaissances dans ce domaine (malgré les quelques code smells dans le programme) !
Mais je reste tout de même très sceptique sur ces 3 derniers articles… J’avoue ne pas avoir lu ceux qui précèdent ces 3 là (outre les 2 premiers), et j’ai aussi bien compris que cet article est plus orienté vers ceux qui voulaient poussé plus loin mais j’ai l’impression que votre guide devient de plus en plus un fourre-tout.
Déjà, ma première question, je me base sur le nom de la série “tuto map aventure”, pourquoi faire des plugins pour une map aventure ? Une map aventure, personnellement je la télécharge sur Internet, je l’installe sur mon jeu et puis je joue dessus, mais en aucun cas j’ai la nécessité d’avoir des plugins pour celle-ci ! J’ai relu l’introduction du premier article, et honnêtement, je ne vois nul part cela spécifier. Moi en tant que débutant dans le domaine du map-making, pourquoi est-il important que je sache faire du Java ?
Dans les deux premiers articles, pourquoi pas, vous expliquez quelques notions de programmation, en faisant le parallèle avec Craftbukkit ou autres API. Vous dites bien au début que cela risque d’être corsé, mais que vous souhaitez vous adressez aux débutants. Vous semblez aimé aller au fond des choses, les faire bien, et dans l’ordre, mais dans ce cas, pourquoi parler de Java et des API Minecraft en même temps ? C’est se tirer une balle dans le pied que de vouloir apprendre les deux en même temps, il est important de connaître le langage avant de l’appliquer sur du Spigot ou autre. À cela, peut-être me répondrez-vous que ce guide donne plus des conseils, qu’il est là pour donner des pistes que les lecteurs pourront explorer de leur côté, et que de toute façon, vous n’avez pas le temps de détailler tout cela, qu’il faut rester accessible aux débutants. Okay, je peux entendre cela mais… Voilà, les personnes lisent votre guide ne savent pas nécessairement programmer en Java, et tout d’un coup, dans ce troisième guide, vous leur parler de Design Patterns, de cycles de production, de réflexion. Ça ne serait pas à l’encontre du fait de vouloir rester accessible au débutant même si ce dernier chapitre se veut un peu plus poussé ? Et même, certaines notions comme la réflexion de Java, pourquoi en parler ici ? Qu’est-ce que cela a à faire dans le développement de plugins ? Alors certes, c’est ce qui est utilisé par Bukkit ou encore Forge pour charger des plugins/mods, mais l’usage de la réflexion est principalement utile dans la conception d’outils et de libraries (injection de dépendances, auto-binding, génération automatique d’accesseurs…). Alors en quoi cela est si important au point d’en parler dans un article qui se veut assez accessible à tous ?
Dans ces 3 articles, j’ai l’impression que vous avez plein de connaissance, et que votre but est d’en partager un maximum. Je ne dis pas que cela est mal, mais que cela ne me semble en tout cas pas nécessaire ici (je suis ouvert à la discussion). Vous voulez rester accessible à tous, mais vous entrez dans des points techniques très précis, et dans des outils qui sont de l’ordre de l’ingénierie logicielle (design pattern, cycle de production, good smells).
Ensuite vous parlez beaucoup du quoi et du comment, mais vous semblez oublier le pourquoi, ce qui est essentiel pour la compréhension : pourquoi cela est nécessaire ? Pourquoi ai-je besoin d’apprendre cela ? En quoi cela m’aidera dans le map-making ?
Des choix non argumentés ne sont pas très pertinents pour le lecteur qui se verra vite perdu car il ne comprendra pas la raison de ceux-ci.
Pur faire un retour un peu plus général de votre guide, je me rends compte que c’est assez à l’image de ces 3 chapitres… Vous avez beaucoup de connaissances accumulés dans votre équipe, vous appliquez des stratégies d’organisation ou de développement très solides mais il ne faut pas oublier quelque chose : Minecraft est un jeu ! Quel est le public ciblé par votre guide ? Vous semblez vouloir qu’il s’adresse aux débutants, mais pour moi en le lisant, il semble plutôt s’adresser à une grosse équipe qui souhaite monter un projet professionnel ; ce qui est loin d’être le cas de la majeure partie des joueurs qui veulent juste partager une idée de map Minecraft. À mon avis, il a l’effet inverse de ce que vous souhaitez, il risque plus de faire fuir les éventuels intéressés par le map-making plutôt que de leur donner de bons conseils qu’ils appliqueront. Ça donne l’image de quelque chose de très professionnel à quelque chose qui est pourtant seulement fait pour s’amuser.
Encore une fois, je ne dis pas que votre guide est mauvais, loin de là ! Mais plutôt que :
Voilà, c’est tout pour moi, je serai ravi d’en discuter plus en détails si vous le souhaitez !
P.S., vous semblez un peu confondre la notion de RayTracing et de RayCasting. À ma connaissance, le RayCasting s’arrête à la première collision pour rendre l’objet là où le RayTracing calcule la réflexion et réfraction du rayon à la collision.
Wow ! J’ai pas tout lu mais le jour où je souhaite développer un plugin minecraft je sais où aller pour apprendre !
Beau travail